Let's have a serious word about Data Democratization
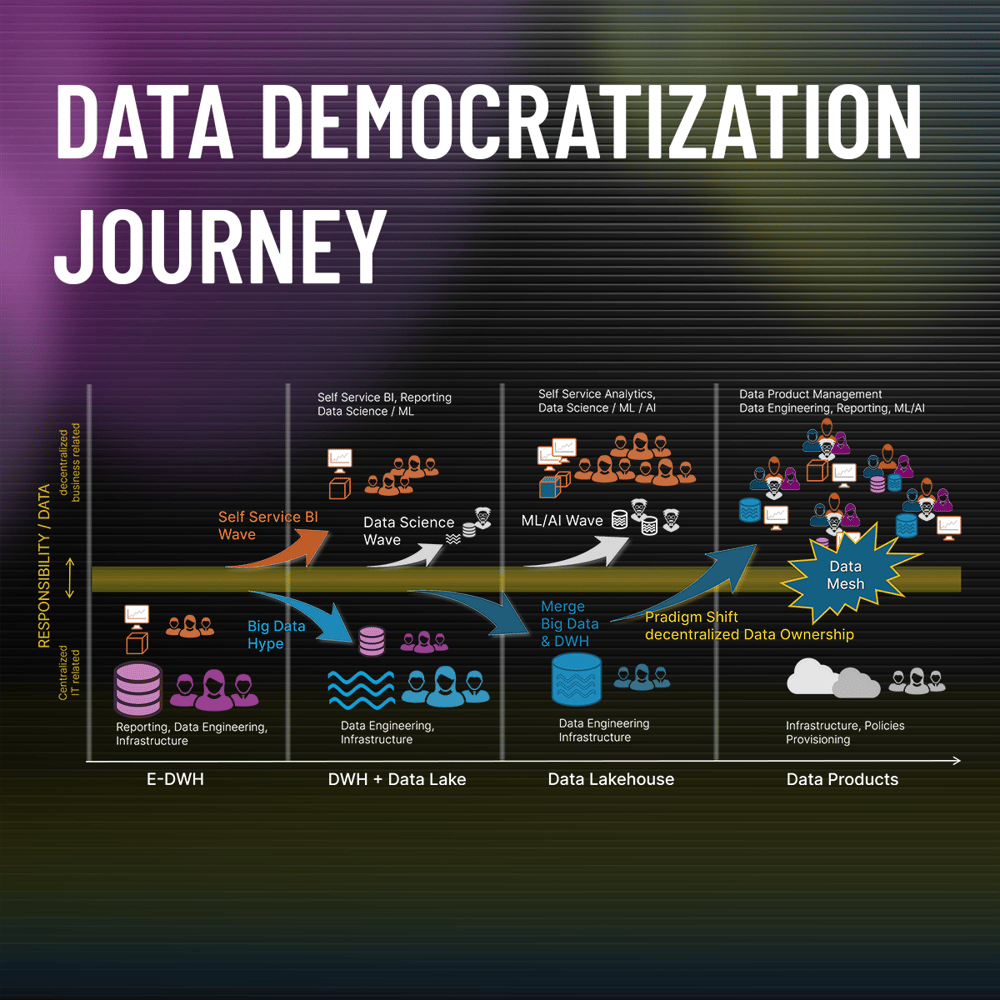
As a child of the super centralized Enterprise Data Warehouse (E-DWH) era, I know the pain points of decentralized data silos very well. The reflexes to centralize data are literally burned into the brain stem, like the flight reflex away from the saber-toothed tiger.
Currently, posts are full of Data Products merged into a wonderful Data Mesh. The entire data world seems to be literally absorbed by Data Democratization.On closer look Data Democratization did not just begin with Zhamak Dehghani's ingenious Data Mesh approach. It all started much earlier.
If you want to benefit from Data Democratization, you need to understand the whole democratization journey. Then you will be able to make the appropriate plans for a successful implementation.
It all started with data centralization
Strange, but that's how it is. The data democratization journey begins with the centralization of data silos into a central Enterprise Data Warehouse (E-DWH). Let's start with the drivers of data centralization in a Data Warehouse:
- With isolated data silos, it was not possible to create cross-data reports, which led to disputes about reporting content.
- As a result, of course, no overarching and consolidated reporting structures were available, which extremely limited analysis.
- In addition, the operational systems had to carry the entire query load, which led to performance bottlenecks.
The Data Warehouse (DWH) solves the problem. Data is neatly integrated, provided with standardized reporting structures, on a very high-performance data platform.
At that time, a centrally organized team of highly qualified and experienced data engineers was responsible for setting up the DWH and the daily operation of the loads. In addition, this team was usually also responsible for setting up the reports.
The catch is that integrating data from many data sources takes a lot of time. The even bigger catch is that all the business areas involved must agree on standardized reporting structures. A never-ending story due to different requirements. And business requirements change every second anyway.
A huge workload that caused the backlogs to grow rapidly and fueled the frustration about the poor delivery service from IT.
The rise of Self-Service BI and the Big Data hype
Somewhere around here, the story of Data Democratization began when software vendors realized that Self-Service BI (in other words, low-code reporting) could help business users get the results they wanted faster in a do-it-yourself mode.
This was true until the threshold was crossed where business users needed more, different, and additional data for their analysis needs. Pressure mounted on data engineers to implement enhancements and changes to the DWH in the shortest possible time. And they failed. Frustration was still high on both sides.
The software industry jumped into the breach again and started the Big Data - Data Lake hype. The motto: Don't waste time curating data, throw everything into one pot and give all business users (often called data scientists back then) access to the big sea of data. We no longer have to worry about what data we really need, because storage is becoming so cheap.
Data Lakehouse makes it smart again
The advantages of big data technologies to store data of different types efficiently were already great. But without a curated DWH, there was still no way around it. The result was a very high level of data redundancy.
Why not combine both concepts in a Data Lakehouse? However, this solution was not primarily a data democratization step, but only an optimization step of centralized data storage.
The final data democratization of this central data storage began afterwards with the data mesh approach and data product thinking.
Dissolving the last bastion – Data Engineering gets decentralized
Handling Data as a Product and assuming Data Ownership. In other words, the assumption of responsibility for the preparation, quality, availability and provision of data by decentralized data product teams is a major paradigm shift.
The last bastion of centralized data engineering has thus fallen. And now, Data Mesh brings us back to the Data Silos in the form of Data Products. All together then available in a Data Marketplace.
End of the pig cycle loop! Back to the roots of siloed data pots!
Well, not quite. The silos are now called data domains and produce data products that at least consist of data sets or even have the data prepared in reports. The result of such data products is offered for consumption in Data Marketplaces. Users or buyers conclude contracts with the data product producers in which not only the content but also the quality and terms of use are regulated.
So things are a little different than they were in the era of data silos many years ago.
What are the main implications of this massive step in Data Democratization?
- Instead of a central team of experts, many smaller data product teams need to be empowered with data infrastructure and data engineering skills.
- Scoping the data domains is a major challenge, both to meet the needs of the data product teams and to avoid creating too much redundancy and inefficiency in the overall data mesh.
- What was achieved in the centralized data world through data integration (e.g., key homogenization) must now be ensured through data product interoperability.
- In the decentralized world of data, Data Governance takes on an additional role, serving as the glue to unify isolated data silos.
- The move to treating data as a product naturally means that there has to be something called Data Product Management. This leads to an intense discussion about cost/benefit and pricing of Data Products.
- Each producer and provider of a data product must also meet formal requirements such as compliance, privacy, access authorization, and data anonymization where appropriate.
- Finally, data product teams must evolve into an operational role, ensuring the quality, freshness, and availability of data sets delivered at an agreed service level.
In summary, this massive step toward data democratization is certainly not an easy one.
Are there alternatives?
No! We need the speed and flexibility to produce data solutions and buy them with the caution we need in a democratized data world to be economically successful.
Given the implications described above, a plan must be developed for successful implementation.
Stay tuned as we go through each point in detail!